● 데이터베이스 드라이버와 JDBC
데이터베이스 드라이버는 애플리케이션과 데이터베이스 사이의 통신을 중개하는 역할을 한다. 데이터베이스 시스템 별로 호환되는 드라이버가 모두 다르니 데이터베이스의 시스템에 맞는 드라이버를 사용해야 한다.
JDBC는 Java 애플리케이션과 데이터베이스 간의 통신을 도와주는 데이터베이스 드라이버다. 개발자는 복잡한 설정 필요없이, 그리고 데이터베이스 시스템 상관없이 JDBC로 데이터베이스와의 연결을 쉽게 구성할 수 있다.
spring-boot-starter-jdbc:
Spring Boot 프로젝트에서 JDBC를 통해 데이터베이스와 상호작용하기 위해 사용되는 스타터 패키지 라이브러리이다.
이 스타터 패키지는 데이터베이스 작업을 수행하는 데 필요한 주요 의존성과 자동 구성 기능을 제공한다.
주요기능:
- JDBC API 지원: JDBC API를 통해 SQL 데이터베이스에 접근하고 작업을 수행한다.
- DataSource 구성: 데이터 소스 연결을 위한 기본적인 설정을 자동으로 구성합니다.
- JdbcTemplate: JdbcTemplate은 Spring의 핵심 클래스 중 하나로, SQL 쿼리 실행, 결과 세트 처리, 예외 처리 등을 단순화한다.
주요 장점 내용:
- 간소화된 데이터베이스 연결: DataSource 설정과 JdbcTemplate 사용을 통해 복잡한 JDBC 코드를 간소화할 수 있다.
- 자동 구성: Spring Boot의 자동 구성 기능은 개발자가 데이터베이스 연결에 필요한 대부분의 구성을 자동으로 처리할 수 있도록 한다.
- 효율적인 예외 처리: Spring의 DataAccessException을 통해 JDBC에서 발생하는 예외를 Spring의 일관된 예외 체계로 변환한다.
JdbcTemplate:
jdbc로 sql을 직접 작성하는 방식에는 여러 문제점이 있다.
- SQL 쿼리 요청시 중복 코드 발생
- DB별 예외에 대한 구분 없이 Checked Exception (SQL Exception) 처리
- Connection, Statement 등.. 자원 관리를 따로 해줘야함
이런 문제들을 해결하기 위해 Persistence Framework가 등장했다.
Persistence Framework에는 두 가지 종류가 있는데
- SQL Mapper : JDBC Template, MyBatis등이 있고
- ORM : JPA, Hibernate 등이 있다.
SQL Mapper는 SQL 문과 객체(Object)의 필드를 매핑하여 데이터를 객체화하는 프레임워크이다.
SQL Mapper 첫번째 주자로 JDBCTemplate 에 RowMapper 탄생했다. 다음은 RowMapper의 특징이다.
- 쿼리 수행 결과와 객채 필드 매핑
- RowMapper 로 응답필드 매핑코드 재사용
- Connection, Statement, ResultSet 반복적 처리 대신 해줌
JdbcTemplate 예시:
@Repository
public class DataRepository {
@Autowired
private JdbcTemplate jdbcTemplate;jdbc 템플릿을 사용하기 전, spring bean객체로 주입받았다.
execute() : 매개변수로 받은 sql문을 그대로 실행한다. 예시:
public void createTable() {
jdbcTemplate.execute("CREATE TABLE IF NOT EXISTS users (id SERIAL, name VARCHAR(255))");
}
update() : 받은 매개변수 값들을 바탕으로 테이블 속 데이터를 수정한다. 예시:
public void insertUser(String name) {
jdbcTemplate.update("INSERT INTO users (name) VALUES (?)", name);
}
public void updateUser(Long id, String newName) {
jdbcTemplate.update("UPDATE users SET name = ? WHERE id = ?", newName, id);
}
public void deleteUser(Long id) {
jdbcTemplate.update("DELETE FROM users WHERE id = ?", id);
}
queryForObject() : sql문을 실행하는데 매개변수를 sql문에 직접 대입하는 대신 객체를 매핑해서 대입한다.
public User findUserById(Long id) {
return jdbcTemplate.queryForObject(
"SELECT * FROM users WHERE id = ?",
new UserRowMapper(), // 이자리에 매퍼를 생성자로 넣어주면 됨
id
);
}
mapRow(): RowMapper 를 상속받아 mapRow() 메서드를 구현하면 JDBCTemplate 에서 row 응답을 mapRow() 메서드에 rs 파라미터로 넘겨주어 객체에 매핑하기 쉽도록 도와준다.
public class UserRowMapper implements RowMapper<User> {
// JDBCTemplate 에서 row 응답을 mapRow() 메서드에 rs 파라미터로 넘겨주어 객체에 매핑하기 쉽도록 도와준다.
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
var user = new User();
user.setId(rs.getInt("ID"));
user.setName(rs.getString("NAME"));
return user;
}
}// 사용자 ID로 User 조회 (Read)
public User findUserById(Long id) {
return jdbcTemplate.queryForObject(
"SELECT * FROM users WHERE id = ?",
new UserRowMapper(), // 이자리에 매퍼를 생성자로 넣어주면 됨
id
);
}
● Raw JPA
MyBatis :
MyBatis 는 RowMapper 가 가지고있는 단점인 “반복되는 코드”를 줄이고 “함께있는 프로그램 코드와 쿼리 코드를 분리하여 관리”하고 싶은 니즈를 반영하여 탄생하였다.
MyBatis의 특징 :
- jdbc로 처리하는 코드의 설정(Connection) 부분을 줄이고 실제 sql문에 연결함으로서 빠른 개발이 가능하게 한다. (SQL Mapper 특징)
- MyBatis 코드는 map 인터페이스(또는 클래스)와 SQL 쿼리와 ResultSet 매핑을 위한 xml 및annotation을 사용한다.
- 다른 방식에 비해 객체자체보다 쿼리에 집중할 수 있다.
MyBatis의 flow chart:

(1) 응용 프로그램이 SqlSessionFactoryBuilder를 위해 SqlSessionFactory를 빌드하도록 요청한다.
(2) SqlSessionFactoryBuilder는 SqlSessionFactory를 생성하기 위한 Mybatis 구성 파일을 읽는다.
다음은 매핑해줄 객체가 들어있는 패키지 경로와 Mapping File 목록을 지정해주는 설정 파일 예시이다.
<!-- /resources/mybatis-config.xml -->
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.thesun4sky.querymapper.domain"/>
</typeAliases>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>
(3) SqlSessionFactoryBuilder는 Mybatis 구성 파일의 정의에 따라 SqlSessionFactory를 생성한다.
(4) 클라이언트가 응용 프로그램에 대한 프로세스를 요청한다.
(5) 응용 프로그램은 SqlSessionFactoryBuilder를 사용하여 빌드된 SqlSessionFactory에서 SqlSession을 가져온다.
(6) SqlSessionFactory는 SqlSession을 생성하고 이를 애플리케이션에 반환한다.
(7) 응용 프로그램이 SqlSession에서 매퍼 인터페이스의 구현 개체를 가져온다.
매퍼 인터페이스의 구현 개체를 가져오는 방법에는 두 가지 방법이 있다.
첫 번째는 DAO 클래스를 정의하는 방법이다. DAO클래스를 가져오면 SqlSession을 직접 다룰 수 있다. SqlSession을 멤버 변수로 사용해서 쿼리 파일 수행을 요청하기 때문이다. 아래는 DAO클래스의 예시이다.
@Component
public class UserDao {
// SqlSession 멤버 변수로 사용하며 쿼리파일 수행 요청
private final SqlSession sqlSession;
public UserDao(SqlSession sqlSession) {
this.sqlSession = sqlSession;
}
public User selectUserById(long id) {
return this.sqlSession.selectOne("selectUserById", id);
}
}두 번째는 매퍼 어노테이션을 활용한 매퍼 인터페이스를 정의하는 방법이다.
매퍼 인터페이스에 org.apache.ibatis.annotations.Mapper 어노테이션을 사용하면 sqlSession을 사용해서 자동으로 호출해준다.
다음은 Mapper어노테이션 사용 예시이다.
// UserMapper.java
@Mapper
public interface UserMapper {
User selectUserById(@Param("id") Long id);
}
(8) 응용 프로그램이 매퍼 인터페이스 메서드를 호출한다.
(9) 매퍼 인터페이스의 구현 개체가 SqlSession 메서드를 호출하고 SQL 실행을 요청한다.
(10) SqlSession은 매핑 파일에서 실행할 SQL을 가져와 SQL을 실행한다.
영속성 컨텍스트:
영속성:
- 데이터를 생성한 프로그램이 종료되어도 사라지지 않는 데이터의 특성을 말한다.
- 영속성을 갖지 않으면 데이터는 메모리에서만 존재하게 되고 프로그램이 종료되면 해당 데이터는 모두 사라지게 된다.
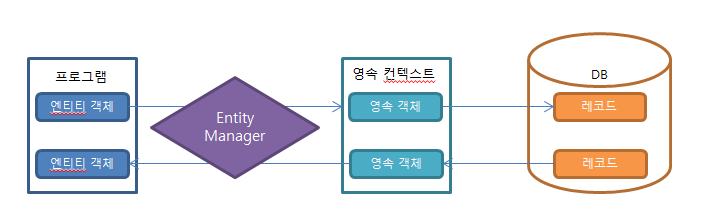
영속성 4가지 상태:
- 비영속(new/transient) - 엔티티 객체가 만들어져서 아직 저장되지 않은 상태로, 영속성컨텍스트와 전혀 관계가 없는 상태
- 영속(managed) - 엔티티가 영속성 컨텍스트에 저장되어, 영속성 컨텍스트가 관리할 수 있는 상태
- 준영속(detached) - 엔티티가 영속성 컨텍스트에 저장되어 있다가 분리된 상태로, 영속성컨텍스트가 더 이상 관리하지 않는 상태
- 삭제(removed) - 엔티티를 영속성 컨텍스트와 데이터베이스에서 삭제하겠다고 표시한 상태
영속성 컨텍스트 예시:
Item item = new Item(); // 영속성 컨텍스트에 담을 상품 엔티티 생성, 비영속 상태
item.setItemNm("테스트 상품");
EntityManager em = entityManagerFactory.createEntityManager(); // 엔티티 매니저 팩토리로부터 엔티티 매니저를 생성
EntityTransaction transaction = em.getTransaction(); // 데이터 변경 시 무결성을 위해 트랜잭션 시작
transaction.begin();
em.persist(item); // 영속성 컨텍스트에 저장된 상태
em.flush(item). // DB에 SQL 보내기/commit시 자동수행되어 생략 가능함
transaction.commit(); // 트랜잭션을 DB에 반영
em.close(); // 매니저와 엔티티 매니저 팩토리 자원을 close() 호출로 반환, 준영속 상태
쓰기 지연:
persist()함수를 통해서 엔티티가 영속 상태가 되는데 이때는 db에서 쿼리가 실행되지 않는다. 이러한 상태를 쓰기 지연이라고 한다.
쓰기 지연이 발생하는 시점:
- flush() 동작이 발생하기 전까지 최적화한다.
- flush() 동작으로 전송된 쿼리는 더이상 쿼리 최적화는 되지 않고, 이후 commit()으로 반영만 가능하다.
쓰기 지연 특징:
- 여러개의 객체를 생성할 경우 모아서 한번에 쿼리를 전송한다.
- 영속성 상태의 객체가 생성 및 수정이 여러번 일어나더라도 해당 트랜잭션 종료시 쿼리는 1번만 전송될 수 있다.
- 영속성 상태에서 객체가 생성되었다 삭제되었다면 실제 DB에는 아무 동작이 전송되지 않을 수 있다.
- 즉, 여러가지 동작이 많이 발생하더라도 쿼리는 트랜잭션당 최적화 되어 최소쿼리만 날라가게된다.
● JPA Repository
기존의 Repository는 entity manager를 활용해서 select, update등 쿼리를 수행하는 메소드를 개발자가 직접 구현해야 했다.(아래는 repository 예시)
@Repository
public class UserRepository {
@PersistenceContext
EntityManager entityManager;
public User insertUser(User user) {
entityManager.persist(user);
return user;
}
public User selectUser(Long id) {
return entityManager.find(User.class, id);
}
}하지만 JPARepository는 상속받으면 SpringDataJpa 에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다.(아래는 jparepository 예시)
// UserRepository.java
public interface UserRepository extends JpaRepository<User, Long> {
// JpaRepository의 상속만으로 기본 메서드는 자동으로 만들어짐
}
RawJPA 테이블 매핑 기능
@Entity:
- 객체 관점에서의 이름
- 디폴트로 클래스명으로 설정됨
@Table:
- RDB 의 테이블 이름
- @Entity의 이름이 테이블의 기본값
- 테이블의 이름은 SQL에서 쓰임
@Id:
- 주키의 생성 방법을 맵핑하는 애노테이션
- 생성 전략과 생성기를 설정할 수 있다
- 기본 전략은 AUTO: 사용하는 DB에 따라 적절한 전략 선택
- 생성 전략에는 AUTO, IDENTITY, SEQUENCE 등이 있다.
@Column:
- 테이블 컬럼의 속성을 정의할 수 있다.
- unique : 중복 허용여부(디폴트:false)
- nullable : null 허용여부(디폴트:true)
- length : 컬럼의 데이터 사이즈
@Column은 String, Date, Boolean, 과 같은 타입들에 공통으로 사이즈 제한, 필드명 지정과 같이 옵션을 설정할 용도로 쓰인다.
@Enumerated는 Enum 매핑용도로 쓰인다. @Enumerated의 속성으로 EnumType.STRING과 EnumType.ORDINAL이 있다.
EnumType.ORDINAL enum의 속성 순서인 번호로 값이 매핑된다.(첫 번째 속성은 0, 두 번째는 1, 세 번째는 2...)
EnumType.STRING은 enum의 속성으로 값이 매핑된다.(자주 사용하는 타입)
복합 값 객체 타입:
복합 값 객체(Composite Value)타입은 엔티티의 멤버로 객체를 넣으면 객체의 멤버들을 db 컬럼으로 매핑을 하는 타입이다.
- @Embeddable : 복합 값 객체로 사용할 클래스 지정
- @Embedded : 복합 값 객체 적용할 필드 지정
@Embeddable 예시:
@Embeddable
public class Address {
private String city;
private String street;
}
- @AttributeOverrides : 복합 값 객체 여러개 지정
- @AttributeOverride : 복합 값 객체 필드명 선언
@Embedded 예시:
@Embedded
@AttributeOverrides({
@AttributeOverride(name = "city", column = @Column(name = "home_city")),
@AttributeOverride(name = "street", column = @Column(name = "home_street")),
}) // 엔티티에는 Address의 city, street에 매핑되고, db에는 home_city, home_street로 컬럼이 지정됨
private Address homeAddress;
@Embedded
@AttributeOverrides({
@AttributeOverride(name = "city", column = @Column(name = "company_city")),
@AttributeOverride(name = "street", column = @Column(name = "company_street")),
}) // 엔티티에는 Address의 city, street에 매핑되고, db에는 company_city, company_street로 컬럼이 지정됨
private Address companyAddress;
Raw JPA 연관관계 매핑 기능
@OneToOne:
- 일대일 관계를 나타내는 매핑 정보
@OneToOne 예시:
// 일대일 단방향
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
@OneToOne
@JoinColumn(name = "LOCKER_ID") // 외래키 컬럼 이름: LOCKER_ID
private Locker locker; // 외래키 주인, Member에서 연관된 Locker로만 조회와 수정가능(반대는 불가)
}
@Entity
public class Locker {
@Id @GeneratedValue
@Column(name = "LOCKER_ID")
private Long id;
private String name;
}// 일대일 양방향
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
@OneToOne
@JoinColumn(name = "LOCKER_ID") // 외래키 컬럼 이름: LOCKER_ID
private Locker locker; // 외래키 주인, Member에서 연관된 Locker로 조회와 수정가능
}
@Entity
public class Locker {
@Id @GeneratedValue
@Column(name = "LOCKER_ID")
private Long id;
private String name;
@OneToOne(mappedBy = "locker") // 외래키 주인이 있는 엔티티의 locker라는 멤버로 매핑됨
private Member member; // Locker에서 연관된 Member로 조회만 가능(수정은 불가)
@OneToMany:
- 일대다 관계를 나타내는 매핑 정보
- 속도를 위해 기본적으로 FetchType 설정이 LAZY 로 설정되어 있다.(Eager로 하면 불필요한 연관 관계의 엔티티들을 모두 불러오느라 속도 저하의 우려가 있음)
- 속성
- mappedBy : 연관관계의 주인 필드를 선택한다.
- fetch : 글로벌 페치 전략 설정
- cascade : 영속성 전이 기능을 사용한다.
- targetEntity : 연관된 엔티티의 타입 정보를 설정한다.
@OneToMany 예시(일대다 양방향 관계는 없음):
// 일대다 단방향 관계
@Entity(name = "parent")
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany
@JoinColumn(name = "parent_id") // 외래키 컬럼 이름: child 테이블의 parent_id
private List<Child> childList; // 외래키 주인, Parent에서 연관된 Child로 조회와 수정가능
}
@Entity(name = "child")
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "parent_id") // 외래키가 실제로 존재하는 곳이지만 외래키 주인은 아님
private Long parentId;
}
@ManyToOne:
- 다대일 관계를 나타내는 매핑 정보
- 속성
- optional (디폴트 값: true) : false로 설정하면 연관된 엔티티가 반드시 있어야 함.
- fetch : 글로벌 패치 전략 설정(디폴트 값: EAGER, 하지만 OneToMany의 케이스와 같은 이유로 LAZY를 주로 씀)
- cascade : 영속성 전이 기능 사용
- targetEntity : 연관된 엔티티의 타입 정보 설정 (targetEntity = Member.class 식으로 사용)
@ManyToOne 예시:
// 다대일 단방향 관계
@Entity(name = "parent")
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
@Entity(name = "child")
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id") // 외래키 컬럼 이름: parent_id
private Parent parent; // 외래키 주인, Child에서 연관된 Parent로 조회와 수정가능// 다대일 양방향 관계
@Entity(name = "parent")
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(mappedBy="parent") // 외래키 주인이 있는 엔티티의 parent라는 멤버로 매핑됨
private List<Child> childList; // Parent에서 연관된 Child로 조회만 가능(수정은 불가)
}
@Entity(name = "child")
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "parent_id") // 외래키 컬럼 이름: parent_id
private Parent parent; // 외래키 주인, Child에서 연관된 Parent로 조회와 수정가능
}
@ManyToMany:
- 다대다 관계를 나타내는 매핑 정보 (N:M)
- 다대다 설정을 하게되면 중간 매핑테이블(JoinTable)이 자동으로 생성된다.
- 중간 매핑 테이블은 JPA상에서 숨겨져서(Entity 정의 없이) 관리된다.(중간 매핑 테이블을 관리하기 불편하다.)
- 이러한 이유 때문에 @ManyToMany 어노테이션 보다는 중간 매핑용 엔티티를 따로 만들어서 엔티티 각자 중간 매핑용 엔티티와 1:N 관계를 맺는 방법을 주로 쓴다.
@ManyToMany 예시:
@Entity
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToMany(mappedBy = "parents") // 외래키 주인 엔티티의 childs 객체로 매핑됨
private List<Child> childs;
}
@Entity
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToMany
@JoinTable(
name = "parent_child", // 중간 테이블 이름: parent_child
joinColumns = @JoinColumn(name = "parent_id"), // 중간 테이블의 외래키 주인쪽 컬럼 이름
inverseJoinColumns = @JoinColumn(name = "child_id") // 중간 테이블의 외래키 주인이 아닌 쪽 컬럼 이름
) // 솔직히 어느쪽이 외래키 주인인지 햇갈림
private List<Parent> parents;
}
자주 사용하는 N:M 구현방법 예시:
@Entity
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(mappedBy = "parent") // 외래키 주인이 있는 엔티티의 parent라는 멤버로 매핑됨
private List<ParentChild> parentChilds; // Parent에서 연관된 ParentChild로 조회만 가능(수정은 불가)
}
@Entity
public class ParentChild {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn("parent_id") // 외래키 컬럼 이름: parent_id
private Parent parent; // 외래키 주인, ParentChild에서 연관된 Parent로 조회와 수정가능
@ManyToOne
@JoinColumn("child_id") // 외래키 컬럼 이름: child_id
private Child child; // 외래키 주인, ParentChild에서 연관된 Child로 조회와 수정가능
}
@Entity
public class Child {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToMany(mappedBy = "child") // 외래키 주인이 있는 엔티티의 child라는 멤버로 매핑됨
private List<ParentChild> parentChilds; // Child에서 연관된 ParentChild로 조회만 가능(수정은 불가)
}
● SpringData JPA:
Cascade (영속성 전이):
영속 상태의 Entity에서 수행되는 작업들이 연관된 Entity까지 전파되는 상황을 의미한다.
- 사용 위치: 연관관계의 주인 반대편(N:1에서 1인 엔티티)
- 사용 조건:
- 양쪽 엔티티의 라이프사이클이 동일하거나 비슷해야한다. (예를들어, 게시글이 삭제되면 첨부파일도 같이 삭제 되어야 한다.)
- 대상 엔티티로의 영속성 전이는 현재 엔티티에서만 전이 되어야 한다. (다른곳에서 또 걸면 안됨, 예를들어, 첨부파일을 게시글이 아닌 다른곳에서 영속성 전이를 하면 안된다.)
- 옵션 종류:
- ALL : 전체 상태 전이
- PERSIST : 저장 상태 전이
- REMOVE : 삭제 상태 전이
- MERGE : 업데이트 상태 전이
- REFERESH : 갱신 상태 전이
- DETACH : 비영속성 상태 전이
orphanRemoval (고아 객체 제거):
- 사용 위치:
- 부모 엔티티(1:N중 1)
- 사용법:
- Cascade.REMOVE와 비슷한 용도로 삭제를 전파하는데 쓰인다.
- 부모 객체에서 리스트 요소삭제를 했을경우 해당 자식 객체는 매핑정보가 없어지므로 대신 삭제해준다.
Cascade.REMOVE와 비슷해 보이지만 사용하는 용도가 다르다.
- Cascade.REMOVE는 부모 객체(1:N중 1)의 객체가 삭제되면 자식 객체(1:N중 N)에 해당하는 모든 객체를 삭제하는 용도이다. (예를 들어 1:N중 1인 게시글 엔티티와 1:N중 N인 첨부파일 엔티티가 있다고 하면 게시글을 지우면 게시글에 첨부되어 있는 모든 첨부파일 엔티티를 삭제한다.)
- orphanRemoval은 부모 객체에서 관계를 끊기 위해 소속된 자식 객체중 하나를 지우면 연관된 부모 엔티티가 더 이상 존재하지 않는 자식 엔티티를 지워버린다. (예를 들어 1:N중 1인 게시글 엔티티에서 첨부된 파일중 하나를 지우면 더 이상 소속된 게시글이 없는 첨부파일 엔티티를 지운다.)
Fetch (조회시점):
Fetch는 엔티티를 조회할 때 연관된 엔티티를 조회하는 시점을 의미한다.
- 옵션(FetchType)
- EAGER : 즉시 로딩 (부모 조회 시 자식도 같이 조회, 한 번의 쿼리로 모두 조회할 수 있음)
- LAZY : 지연 로딩 (자식은 필요할때 따로 조회, 연관된 엔티티가 하나 늘어날 때 마다 쿼리 호출 횟수가 하나씩 늘어난다.)
- 사용 위치
- Entity 에 FetchType 으로 설정할 수 있다.
- @ManyToMany, @OneToMany, @ManyToOne, @OneToOne
- Query 수행시 fetch Join 을 통해서 LAZY 인 경우도 즉시 불러올 수 있다.
- Entity 에 FetchType 으로 설정할 수 있다.
- 사용법
- 기본 LAZY를 설정한 뒤에 필요할때만 fetch Join 을 수행한다.
- 항상 같이 쓰이는 연관관계 일 경우만 EAGER 를 설정한다.
JpaRepository 쿼리:
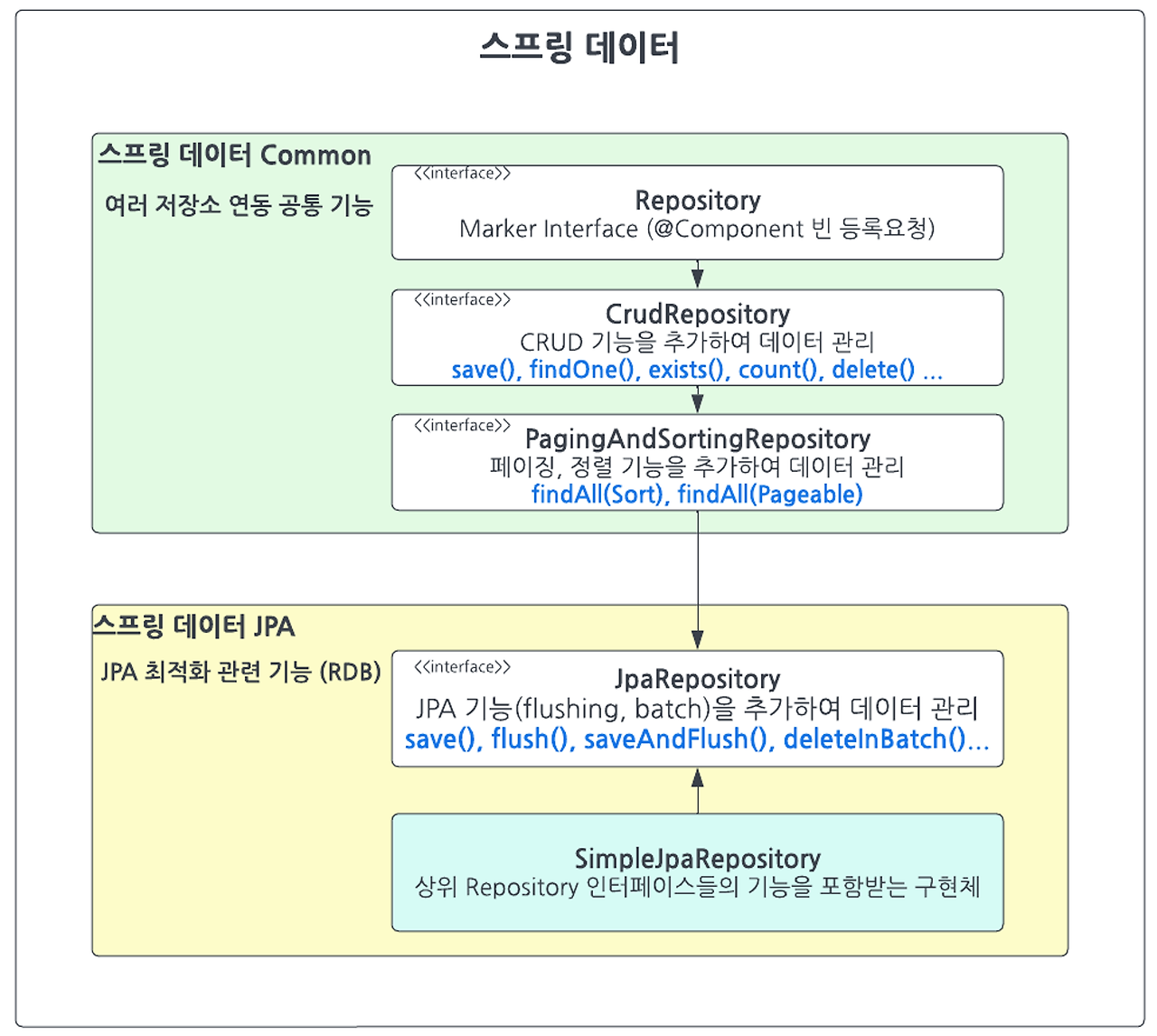
SprintData Common 의 CRUDRepository와 PagingAndSortingRepository 이 쿼리기능을 제공
Repository ~ JpaRepository 까지는 @NotRepositoryBean 이 붙어있는 인터페이스이다.
JpaRepository<Entity,ID> 인터페이스를 Repository 인터페이스에 상속한다. 상속을 하게 되면 @NotRepositoryBean이 붙은 상위 인터페이스들의 기능을 포함한 구현체가 프로그래밍된다.
그리고 SpringDataJpa에 의해 엔티티의 CRUD, 페이징, 정렬 기능 메소드들을 가진 빈이 등록된다.
JpaRepository 쿼리 사용 방법:
JpaRepository 쿼리는 일정한 규칙에 따라 프로그래밍 되어 쿼리 메소드를 제공한다.
규칙 : 리턴타입 {접두어}{도입부}By{프로퍼티 표현식}(조건식)[(And|Or){프로퍼티 표현식}(조건식)](OrderBy{프로퍼티}Asc|Desc) (매개변수...)
| 접두어 | Find, Get, Query, Count, .. |
| 도입부 | Distinct, First(N), Top(N) |
| 프로퍼티 표현식 | Person.Address.ZipCode => find(Person)ByAddress_ZipCode(...) |
| 조건식 | IgnoreCase, Between, LessThan, GreaterThan, Like, Contains, ... |
| 정렬 조건 | OrderBy{프로퍼티}Asc |
| 리턴 타입 | E, Optional<E>, List<E>, Page<E>, Slice<E>, Stream<E> |
| 매개변수 | Pageable, Sort |
예시:
// 기본
List<User> findByNameAndPassword(String name, String password);
// distinct (중복제거)
List<User> findDistinctUserByNameOrPassword(String name, String password);
List<User> findUserDistinctByNameOrPassword(String name, String password);
// ignoring case (대소문자 무시)
List<User> findByNameIgnoreCase(String name);
List<User> findByNameAndPasswordAllIgnoreCase(String name, String password);
// 정렬
List<Person> findByNameOrderByNameAsc(String name);
List<Person> findByNameOrderByNameDesc(String name);
// 페이징
Page<User> findByName(String name, Pageable pageable); // Page 는 카운트쿼리 수행됨
Slice<User> findByName(String name, Pageable pageable); // Slice 는 카운트쿼리 수행안됨
List<User> findByName(String name, Sort sort);
List<User> findByName(String name, Pageable pageable);
// 스트림 (stream 다쓴후 자원 해제 해줘야하므로 try with resource 사용추천)
Stream<User> readAllByNameNotNull();
Pageable:
- Pageable은 페이지네이션을 간편하게 구현하기 위해 만들어진 인터페이스이다.
- PageRequest 객체를 repository 메소드에 파라미터로 넘기면 페이지네이션을 구현할 수 있다.
- PageRequest 객체는 요청된 페이지 숫자와 페이지 사이즈를 넘김으로서 만든다. (페이지 숫자는 0부터 시작한다.)
Pageable예시:
// 첫 페이지 (페이지 사이즈 = 2)
Pageable firstPageWithTwoElements = PageRequest.of(0, 2);
// 두번째 페이지 (페이지 사이즈 = 5)
Pageable secondPageWithFiveElements = PageRequest.of(1, 5);
// 페이지 사용
List<Product> allTenDollarProducts =
productRepository.findAllByPrice(10, secondPageWithFiveElements);
findAll(Pageable pageable) 메소드는 기본적으로 Page 객체를 리턴한다.
하지만 Page 인스턴스는 Product 의 목록 뿐 아니라 페이징할 수 있는 전체 목록의 숫자 정보도 포함되어 있기 때문에 Product만을 리턴하기 위한 쿼리 작업이 필요하다.
그래서 예시처럼 커스텀 메소드를 통해 List로 반환하도록 만든다.
Sorting
쿼리 결과를 정렬하기 위해선 Sort 객체를 메소드에 전달한다.
페이지네이션과 정렬을 동시에 하고 싶으면 정렬에 대한 디테일 정보를 PageRequest 객체에 전달하면 된다.
정렬만 하려는 경우 위에 언급한 findAll(Sort sort) 메서드와 같이 Sort 객체만 파라미터로하는 메서드를 작성하면 된다.
Sorting 예시:
Pageable sortedByName = PageRequest.of(0, 3, Sort.by("name"));
Pageable sortedByPriceDesc = PageRequest.of(0, 3, Sort.by("price").descending());
Pageable sortedByPriceDescNameAsc = PageRequest.of(0, 5, Sort.by("price").descending().and(Sort.by("name")));
Page<Product> allProductsSortedByName = productRepository.findAll(Sort.by("name").accending());
JPQL:
JPQL(Java Persistence Query Language)은 Table 이 아닌 Entity(객체) 기준으로 작성하는 쿼리를 JPQL 이라고 하며 이를 사용할 수 있도록 EntityManger 또는 @Query 구현체를 통해 JPQL 쿼리를 사용할 수 있다.
EntityManager를 활용한 JPQL작성:
- EntityMananger.createQuery()를 사용하고 매개변수로 쿼리 문자열과 엔티티 객체를 받는다.
- setParameter 와 같이 key, value 문자열을 통해서 쿼리 파라미터를 매핑할 수 있다.
예시:
@Test
public void testEmCreateQuery() {
String qlString = "select u from User u " +
"where u.username = :username";
Member findUser = em.createQuery(qlString, User.class)
.setParameter("username", "teasun")
.getSingleResult();
assertThat(findUser.getUsername()).isEqualTo("teasun");
}@Query 어노테이션을 활용한 JPQL작성:
- @Query의 속성값으로 간단하게 쿼리를 작성할 수 있다.
- 쿼리를 작성할때는 테이블명이 아니라 Entity 명으로 조회하게 된다.
위의 두 방법들은 sql쿼리가 잘못 작성한건지 아닌지 컴파일 시점에서는 알 수 없다. 저 코드가 실제로 실행되는 런타임 시점에 되서야 오류가 나고 런타임 오류는 어느 쪽에서 문제가 생긴건지 컴파일 오류에 비해 상대적으로 찾기 어렵다.
해결책으로는
- 문자열을 포함하여 구현된 기능들은 객체화 또는 함수화 해서 컴파일시 체크되도록 한다.
- 문자열로 선언된 변수들은 상수로 선언하여 공통적으로 관리한다.
이 있다. 이런 해결책으로 나온 기능이 바로 QueryDSL이다.
● SpringData JPA 심화:
QueryDSL:
QueryDSL은 Entity 의 매핑정보를 활용하여 쿼리에 적합하도록 쿼리 전용 클래스(Q클래스)로 재구성해주는 기술이다. 그리고 JPAQueryFactory 을 통한 Q클래스를 활용할 수 있는 기능들을 제공한다.
JPAQueryFactory:
재구성한 Q클래스를 통해 문자열이 아닌 객체 또는 함수로 쿼리를 작성하고 실행하게 해주는 기술이다.
QueryDSL 예시:
@PersistenceContext
EntityManager em;
public List<User> selectUserByUsernameAndPassword(String username, String password){
JPAQueryFactory jqf = new JPAQueryFactory(em);
QUser user = QUser.user;
List<Person> userList = jpf
.selectFrom(user)
.where(person.username.eq(username)
.and(person.password.eq(password))
.fetch();
return userList;
}
JPAQueryFactory객체를 bean으로 등록하고 주입받는 방법도 있다.
// configuration 패키지안에 추가
@Configuration
public class JPAConfiguration {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}Auditing:
Auditing을 사용하면 엔티티를 생성/마지막 수정 시간과 생성/마지막 수정한 사용자를 자동으로 기록되게 할 수 있다.
Auditing 예시:
메인 애플리케이션 위에 @EnableJpaAuditing을 추가해야 한다.
@EnableJpaAuditing
@SpringBootApplication
public class Application {
...
엔티티 클래스 위에 @EntityListeners(AuditingEntityListener.class)를 추가해야 한다.
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public class TimeStamp {
@CreatedDate
private LocalDateTime createdAt;
@CreatedBy
@ManyToOne
private User createdBy;
@LastModifiedDate
private LocalDateTime modifiedAt;
@LastModifiedBy
@ManyToOne
private User modifiedBy;
}이제 생성, 수정시간을 기록하고 싶은 엔티티에 저 TimeStamp객체를 상속받으면 생성, 수정시간이 기록된다.
생성, 수정한 사용자의 정보가 담긴 createdAt과 updatedAt은 AuditorAware 구현체가 필요하다.
예시에서는 SecurityContextHolder 에서 인증정보안에 담긴 UserDetailsImpl 을 사용하여 user 객체를 가져와서 넣어준다.
@Service
public class UserAuditorAware implements AuditorAware<User> {
@Override
public Optional<User> getCurrentAuditor() {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
if (authentication == null || !authentication.isAuthenticated()) {
return Optional.empty();
}
return Optional.of(((UserDetailsImpl) authentication.getPrincipal()).getUser());
}
}SecurityContextHolder에 인증된 사용자 정보를 넣는 코드:
// JwtAuthFilter.java
@Slf4j
@RequiredArgsConstructor
public class JwtAuthFilter extends OncePerRequestFilter {
private final JwtUtil jwtUtil;
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String token = jwtUtil.resolveToken(request);
if(token != null) {
if(!jwtUtil.validateToken(token)){
jwtExceptionHandler(response, "Token Error", HttpStatus.UNAUTHORIZED.value());
return;
}
Claims info = jwtUtil.getUserInfoFromToken(token);
// 인증정보 세팅함수 호출
setAuthentication(info.getSubject());
}
try {
filterChain.doFilter(request, response);
}catch(FileUploadException e){
jwtExceptionHandler(response,"File Upload Error",400);
}
}
public void setAuthentication(String username) {
// SecurityContextHolder 는 threadLocal 로 구현되어 요청쓰레드내에서 공유할 수 있다.
SecurityContext context = SecurityContextHolder.createEmptyContext();
Authentication authentication = jwtUtil.createAuthentication(username);
// 요기서 인증정보(계정정보)를 담아준다.
context.setAuthentication(authentication);
SecurityContextHolder.setContext(context);
}
...
}
'내일배움캠프' 카테고리의 다른 글
| Trello프로젝트(심화 프로젝트) 2일차 (0) | 2024.07.11 |
|---|---|
| Trello프로젝트(심화 프로젝트) 1일차 (0) | 2024.07.11 |
| querydsl로 동적 정렬 구현 (0) | 2024.07.05 |
| 아웃소싱 프로젝트 4일차 (0) | 2024.06.26 |
| 아웃소싱 프로젝트 5일차(KPT회고) (0) | 2024.06.25 |


